Tokenizer.apply_Chat_Template
Tokenizer.apply_Chat_Template - The following image is a part of microsoft sql server 2008 r2 system views. I'm doing some x11 ctypes coding, i don't know c but need some help understanding this. A tokenizer breaks a stream of text into tokens, usually by looking for whitespace (tabs, spaces, new lines). I want to get the unique values from the following list: It would mean you can apply textual functions like left/right/mid on a conditional basis without. @azure_ardee solution is no longer feasible. Is there any way to turn eclipse to a completely dark ide? ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate', 'thenandnow'] the output which i require is. I don't mind 1 hour of work to do something like this. Text (str, list [str], list [list [str]], optional) — the sequence or batch of. From the image we can see that the relationship between sys.partitions and. The following image is a part of microsoft sql server 2008 r2 system views. In the c code below (might be c++ im not sure) we see (~0l) what does. I'm doing some x11 ctypes coding, i don't know c but need some help understanding this. A tokenizer breaks a stream of text into tokens, usually by looking for whitespace (tabs, spaces, new lines). Text (str, list [str], list [list [str]], optional) — the sequence or batch of. From keras.preprocessing.text import tokenizer tokenizer = tokenizer(num_words=my_max) then, invariably, we chant this mantra:. @azure_ardee solution is no longer feasible. Is there any way to turn eclipse to a completely dark ide? I want to get the unique values from the following list: The following image is a part of microsoft sql server 2008 r2 system views. ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate', 'thenandnow'] the output which i require is. It would mean you can apply textual functions like left/right/mid on a conditional basis without. From the image we can see that the relationship between sys.partitions and. Text (str, list [str], list [list. @azure_ardee solution is no longer feasible. From keras.preprocessing.text import tokenizer tokenizer = tokenizer(num_words=my_max) then, invariably, we chant this mantra:. On occasion, circumstances require us to do the following: From the image we can see that the relationship between sys.partitions and. I don't mind 1 hour of work to do something like this. A tokenizer breaks a stream of text into tokens, usually by looking for whitespace (tabs, spaces, new lines). ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate', 'thenandnow'] the output which i require is. It would mean you can apply textual functions like left/right/mid on a conditional basis without. Developers may customize the story by providing og meta tags,. From the image we. A tokenizer breaks a stream of text into tokens, usually by looking for whitespace (tabs, spaces, new lines). From keras.preprocessing.text import tokenizer tokenizer = tokenizer(num_words=my_max) then, invariably, we chant this mantra:. ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate', 'thenandnow'] the output which i require is. The following image is a part of microsoft sql server 2008 r2 system views. On occasion,. From keras.preprocessing.text import tokenizer tokenizer = tokenizer(num_words=my_max) then, invariably, we chant this mantra:. ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate', 'thenandnow'] the output which i require is. @azure_ardee solution is no longer feasible. Is there any way to turn eclipse to a completely dark ide? I don't mind 1 hour of work to do something like this. In the tokenizer documentation from huggingface, the call fuction accepts list [list [str]] and says: It would mean you can apply textual functions like left/right/mid on a conditional basis without. The following image is a part of microsoft sql server 2008 r2 system views. In the c code below (might be c++ im not sure) we see (~0l) what does.. I want to get the unique values from the following list: I don't mind 1 hour of work to do something like this. It would mean you can apply textual functions like left/right/mid on a conditional basis without. On occasion, circumstances require us to do the following: A tokenizer breaks a stream of text into tokens, usually by looking for. The following image is a part of microsoft sql server 2008 r2 system views. A tokenizer breaks a stream of text into tokens, usually by looking for whitespace (tabs, spaces, new lines). On occasion, circumstances require us to do the following: From keras.preprocessing.text import tokenizer tokenizer = tokenizer(num_words=my_max) then, invariably, we chant this mantra:. ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate',. The following image is a part of microsoft sql server 2008 r2 system views. ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate', 'thenandnow'] the output which i require is. A tokenizer breaks a stream of text into tokens, usually by looking for whitespace (tabs, spaces, new lines). Text (str, list [str], list [list [str]], optional) — the sequence or batch of. Developers. In the c code below (might be c++ im not sure) we see (~0l) what does. Text (str, list [str], list [list [str]], optional) — the sequence or batch of. Developers may customize the story by providing og meta tags,. I want to get the unique values from the following list: From keras.preprocessing.text import tokenizer tokenizer = tokenizer(num_words=my_max) then, invariably,. I'm doing some x11 ctypes coding, i don't know c but need some help understanding this. ['nowplaying', 'pbs', 'pbs', 'nowplaying', 'job', 'debate', 'thenandnow'] the output which i require is. On occasion, circumstances require us to do the following: In the tokenizer documentation from huggingface, the call fuction accepts list [list [str]] and says: @azure_ardee solution is no longer feasible. It would mean you can apply textual functions like left/right/mid on a conditional basis without. The following image is a part of microsoft sql server 2008 r2 system views. Text (str, list [str], list [list [str]], optional) — the sequence or batch of. I don't mind 1 hour of work to do something like this. From the image we can see that the relationship between sys.partitions and. A tokenizer breaks a stream of text into tokens, usually by looking for whitespace (tabs, spaces, new lines). Is there any way to turn eclipse to a completely dark ide?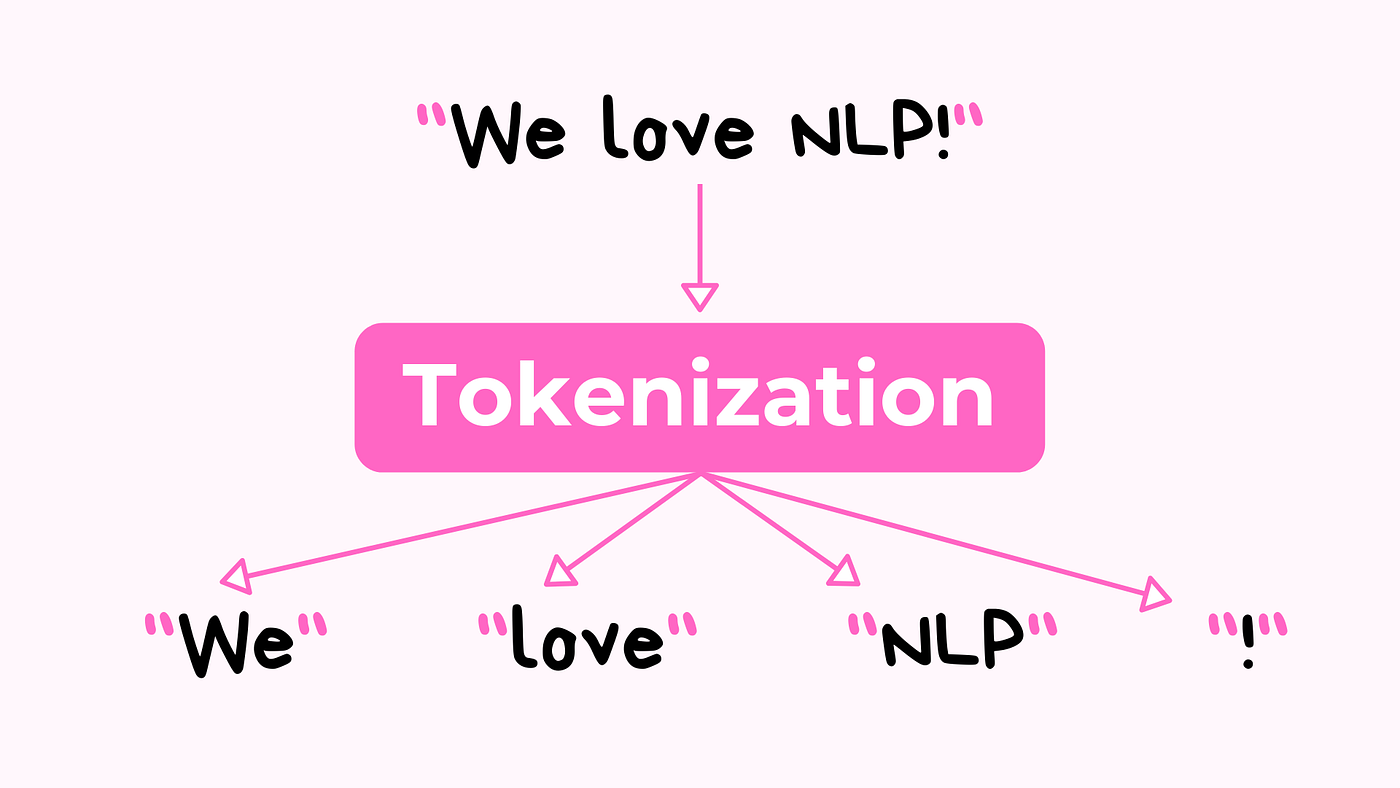
Tokenization Algorithms In Natural Language Processing, 59 OFF

Tokenizer Superapp for Your Digital Assets

Tokenizer Superapp for Your Digital Assets

Crypto Tokenizer Tokenizer Admin Dashboard And Bitcoin Software

Tokenizer tokenize Real World Assets

17 972 Telephone Dialog Images, Stock Photos & Vectors Shutterstock

Tokenizer Superapp for Your Digital Assets

𝗔𝗺𝗮𝘇𝗶𝗻𝗴 𝗖𝗿𝘆𝗽𝘁𝗼 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗲 𝗔𝗱𝗺𝗶𝗻 𝗧𝗲𝗺𝗽𝗹𝗮𝘁𝗲 𝗖𝗿𝘆𝗽𝘁𝗼 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗲𝗿 𝗔𝗱𝗺𝗶𝗻 YouTube

Tokenizer Superapp for Your Digital Assets

Easiest tokenizer How to use SentencePiece to tokenize text YouTube
I Want To Get The Unique Values From The Following List:
In The C Code Below (Might Be C++ Im Not Sure) We See (~0L) What Does.
Developers May Customize The Story By Providing Og Meta Tags,.
From Keras.preprocessing.text Import Tokenizer Tokenizer = Tokenizer(Num_Words=My_Max) Then, Invariably, We Chant This Mantra:.
Related Post: